Chapter 1: Overview: Artificial Intelligence in Research
If you’ve been paying attention to conversations in your department lately, you’ve probably noticed that AI keeps coming up. Whether you are a faculty member, a postdoc, or a graduate student, you are likely hearing about it in seminars, in lab meetings, and in discussions about how research itself is changing. This chapter is meant to give you a grounded starting point: what AI actually is, why researchers across disciplines are adopting it, what it genuinely does well and what it doesn’t, and how to think about using it responsibly. It also gives you a map of the rest of this handbook so you can navigate straight to whatever is most useful to you right now.
What Is “AI,” Anyway?
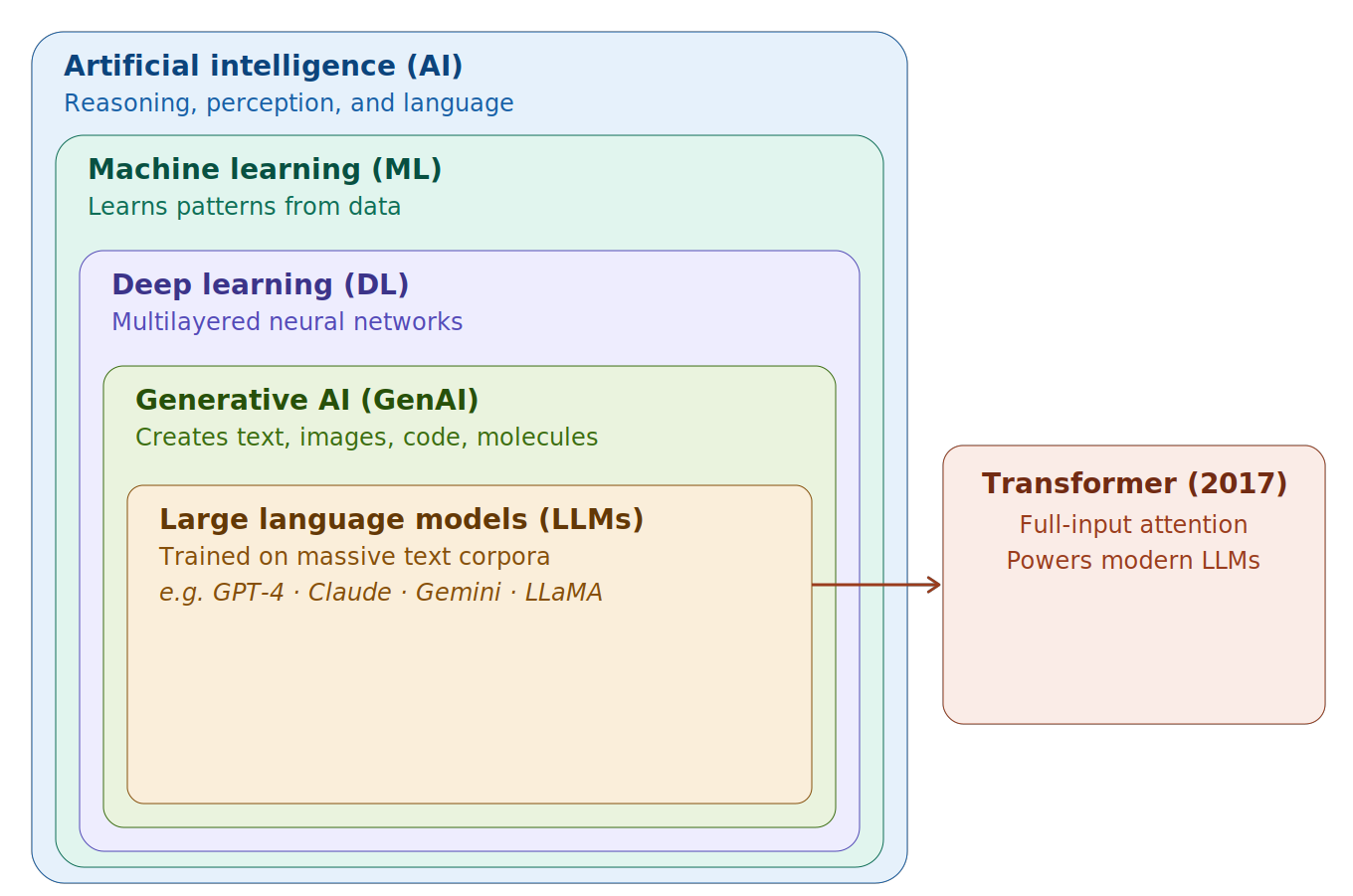
The terminology around AI can feel like a moving target, so it’s worth a quick orientation. The way to think about it is as a set of nested categories, each one more specific than the last.
Artificial intelligence is the broadest term. It refers to computational systems designed to carry out tasks that would normally require human-like reasoning, perception, or language understanding [Russell and Norvig, 2021]. Machine learning sits inside that category. Rather than following hand-crafted rules, machine learning systems improve by finding patterns in data; they learn from examples rather than being explicitly programmed. Deep learning is a specific type of machine learning that uses multilayer neural networks to build up rich, layered representations of information. It’s what powers modern image recognition, speech processing, and natural language systems.
Within deep learning, generative AI refers to models that can produce new content, including text, images, code, and molecular structures, by learning the statistical structure underlying existing data. Some of the earliest generative models were Generative Adversarial Networks, introduced in 2014 [Goodfellow and others, 2014]. The category really took off with Large Language Models (LLMs): massive neural networks trained on enormous text corpora to understand and generate language. GPT-3 was one of the first to demonstrate that these models could handle a wide range of tasks with minimal task-specific training.
What made all of this possible at scale was an architectural breakthrough from 2017 called the Transformer. Unlike earlier approaches that processed text word by word, Transformers can attend to all parts of an input simultaneously, making them both more capable and much more efficient to train at large scale. Combine that with the parallel computing power of modern GPUs, and you have the two ingredients that explain why AI has advanced so quickly and why LLMs are now showing up across the research enterprise.
Why Researchers Are Turning to AI
The short answer is that research has a scale problem. Scientific literature is growing faster than any individual researcher can track, datasets are larger and more complex than ever, and the pressure to move quickly has not let up. AI doesn’t solve all of that, but it does genuinely change the equation in several ways.
The most obvious change is speed. AI can scan, summarize, and surface patterns across bodies of text or data that would take a human researcher weeks to process manually. Research has found that papers using AI-assisted methods tend to receive higher citation impact, and the share of AI-driven work has grown sharply since around 2015 [Hao et al., 2025]. But the more interesting shift is qualitative. AI can reveal patterns in complex, multimodal datasets (genomics, medical imaging, social media streams, environmental sensors) that classical statistical approaches might not detect. It opens up research questions that were previously intractable not because they weren’t worth asking, but because the data was too complex to work with.
Beyond analysis, AI has become a practical assistant across almost every phase of the research workflow. It can help with literature screening, early-stage data wrangling, drafting and editing prose, writing and debugging code, and structuring arguments (Smeds et al., 2023). Because these tools are increasingly accessible through standard platforms, researchers in fields that have traditionally been less computationally oriented (the humanities, social sciences, qualitative health research) can now engage with methods that weren’t realistic before [França, 2023].
The framing we use throughout this handbook is that AI works best as a collaborator, not a replacement. It amplifies what you can do; it doesn’t substitute for your domain expertise, your judgment about what questions matter, or your responsibility for what you produce.
What AI Can and Cannot Do
It’s easy to come away from a well-performing language model demo thinking these systems are more capable than they actually are. Here is an honest account of both sides.
On the capability side, AI is genuinely good at processing large volumes of text and data, identifying patterns and relationships, generating drafts, translating between formats, and surfacing relevant literature. It can suggest analytical approaches you might not have considered, and it can accelerate prototyping considerably.
On the limitation side, the list is important enough to take seriously. AI models can produce confident-sounding outputs that are simply wrong. The well-documented phenomenon of “hallucinations,” where a model generates plausible but fabricated information including fake citations, is a real hazard in research contexts [França, 2023]. Models trained on biased data can perpetuate and amplify those biases in ways that are not always visible. Many systems are difficult to interpret, which creates real challenges for reproducibility and scientific transparency. And there is a genuine concern worth sitting with: as AI tools make certain tasks faster and easier, there is a real question about whether researchers are developing the deeper understanding their work actually requires [Yale News, 2024].
None of this means you should avoid AI. It means you should use it thoughtfully, document your workflows, validate outputs carefully, and stay critically engaged with what the tool is actually doing.
What AI does well |
Where it falls short |
|
|---|---|---|
Scale |
Processing large volumes of text and data |
Reasoning about genuinely novel problems |
Pattern recognition |
Finding relationships in complex datasets |
Understanding causation or context |
Efficiency |
Drafting, summarizing, formatting |
Guaranteeing factual accuracy |
Accessibility |
Lowering barriers across disciplines |
Replacing domain expertise and judgment |
Should You Trust AI with Your Research?
One concern that comes up regularly, especially among researchers working with sensitive or unpublished material, is whether using AI tools is safe from a data privacy standpoint. It’s a reasonable concern. Scientific innovation depends on protecting emerging hypotheses, unpublished datasets, and grant-sensitive intellectual work.
The honest answer is that it depends on the tool and the context, and the distinctions matter. Reputable AI providers operating through enterprise or institution-managed environments offer explicit assurances that user inputs are not used to train future models [Kethireddy, 2020]. From a technical standpoint, frontier models are trained on data with a fixed cutoff date and do not learn from your conversation in real time. That said, data retention policies vary across providers and product tiers, and not all tools offer the same level of protection. Before using any AI tool with sensitive research data, including unpublished manuscripts, identifiable human subjects data, or proprietary datasets, it is worth checking the provider’s current data use policy and consulting your IRB or data governance office where applicable.
For highly sensitive content, university-managed or on-premise deployments offer the strongest guarantees. For everyday research tasks like literature exploration, drafting, or code assistance, mainstream enterprise tools are generally appropriate with standard precautions. Knowing which tier of tool to use for which task is part of working responsibly with AI, and it’s something we return to in the ethics and privacy chapter.
Trusting AI is not an all-or-nothing judgment. It means understanding what safeguards are in place, using the right tool for the right task, and documenting your process.
If You’re at U-M
The University of Michigan has made substantial investments in AI for research, including campus-hosted tools, secure computing infrastructure, and expert consulting services [University of Michigan Office of Research, 2024]. Part IV of this handbook walks through those resources in detail. See AI Resources at the University of Michigan.
What’s in the Rest of This Handbook
This chapter has given you the landscape. The chapters that follow get progressively more specific and practical.
Part I: AI Across the Research Lifecycle covers the strategic and process side. Chapter 2 is a conceptual introduction to how modern AI actually works, and Chapter 3 goes into prompt engineering. Chapter 4 helps you decide when and whether to use AI for a given task, and what questions to ask before you start. Chapters 5, 6, and 7 go deep on three of the most common applications in research practice: AI-assisted literature review, research planning, and writing and communication. Chapter 8 focuses specifically on grant writing with AI, which comes with its own norms and agency policies worth understanding. Chapters 9, 10, and 11 address peer review with AI, ethics and privacy, and validation, three themes that come up in every other part of this handbook.
Part II: AI in Data Analysis is the hands-on section. It starts with how to access and work with data (Chapters 12 and 13), moves through exploratory analysis, data preparation, and feature engineering (Chapters 14 through 16), and then gets into analysis workflows: AutoML for tabular, time series, and multimodal data, pre-trained models for text and vision, and validation and interpretation (Chapters 17 through 21). Chapter 22 covers reproducibility. These chapters assume basic familiarity with Python but are designed to be accessible even if you are not primarily a data scientist.
Part III: Building with Modern AI goes deeper into the building blocks behind AI-powered research tools. Chapter 23 covers NLP with pre-trained language models, Chapter 24 introduces retrieval-augmented generation, Chapter 25 covers AI agents and multi-step research workflows, and Chapter 26 addresses LLM evaluation and fine-tuning. These chapters are more technical and assume you are comfortable with the material in Part II.
Part IV: Resources and Reference is where you will find the U-M-specific resource guide, curated external tools and readings, templates you can adapt directly, and a glossary of key terms (Chapters 27 through 30).
You do not need to read this handbook from beginning to end. Each chapter is designed to stand on its own, so if you already have a specific task in mind, like working through a data analysis pipeline, preparing a grant with AI assistance, or thinking through the ethics of a particular project, you can jump straight to the relevant chapter and get what you need.
References
Stuart Russell and Peter Norvig. Artificial Intelligence: A Modern Approach. Pearson, 4 edition, 2021.
Ian Goodfellow and others. Generative adversarial nets. Advances in Neural Information Processing Systems, 2014.
Qianyue Hao, Fengli Xu, Yong Li, and James Evans. Artificial intelligence tools expand scientists' impact but contract science's focus. 2025. URL: https://arxiv.org/abs/2412.07727, arXiv:2412.07727.
César França. Ai empowering research: 10 ways how science can benefit from ai. 2023. URL: https://arxiv.org/abs/2307.10265, arXiv:2307.10265.
Yale News. Doing more, learning less? the risks of AI in research. 2024. Accessed 2025-01-01. URL: https://news.yale.edu/2024/03/07/doing-more-learning-less-risks-ai-research.
R. R. Kethireddy. Privacy-preserving ai techniques for secure data sharing in healthcare. Journal of Recent Trends in Computer Science and Engineering, 8(2):41–51, 2020.
University of Michigan Office of Research. Going all-in on AI: how the university of michigan is integrating artificial intelligence across its research enterprise. 2024. Accessed 2025-01-01. URL: https://research.umich.edu/research-stories/going-all-in-on-ai/.