Chapter 15: Data Preparation with AI Assistance
What You’ll Learn
How to make strategic decisions about data cleaning (not just how to code it)
A three-way framework: discuss with AI, hand off simple tasks, collaborate on complex ones
How to validate transformations without blindly trusting AI output
The importance of documenting every cleaning decision
What vibe coding is and where it fits within a research workflow
The Real Work Begins
In Chapter 14, you built a mental model of your dataset. You described every column in plain language, identified your target variable, and flagged the issues that need fixing before you can trust anything downstream. That checklist is your starting point here.
Now comes the preparation phase. But the key insight is this: the hardest part of data prep is not the coding. It is deciding what to do about each issue and why. A survey dataset might have 15% of respondents leaving a key income question blank. Do you drop those rows, impute the median, or add a “not reported” category? The answer depends on your research design, not on what code is most convenient to write. That is where AI becomes genuinely useful as a thinking partner, not just a code generator.
The Three-Way Framework
Not all data cleaning tasks are created equal. Some require careful reasoning with AI as your guide. Others are mechanical and you can hand them off with minimal oversight. A third group sits in the middle, where you and AI work through the problem together. Knowing which task falls into which category will save you time and protect your data integrity.
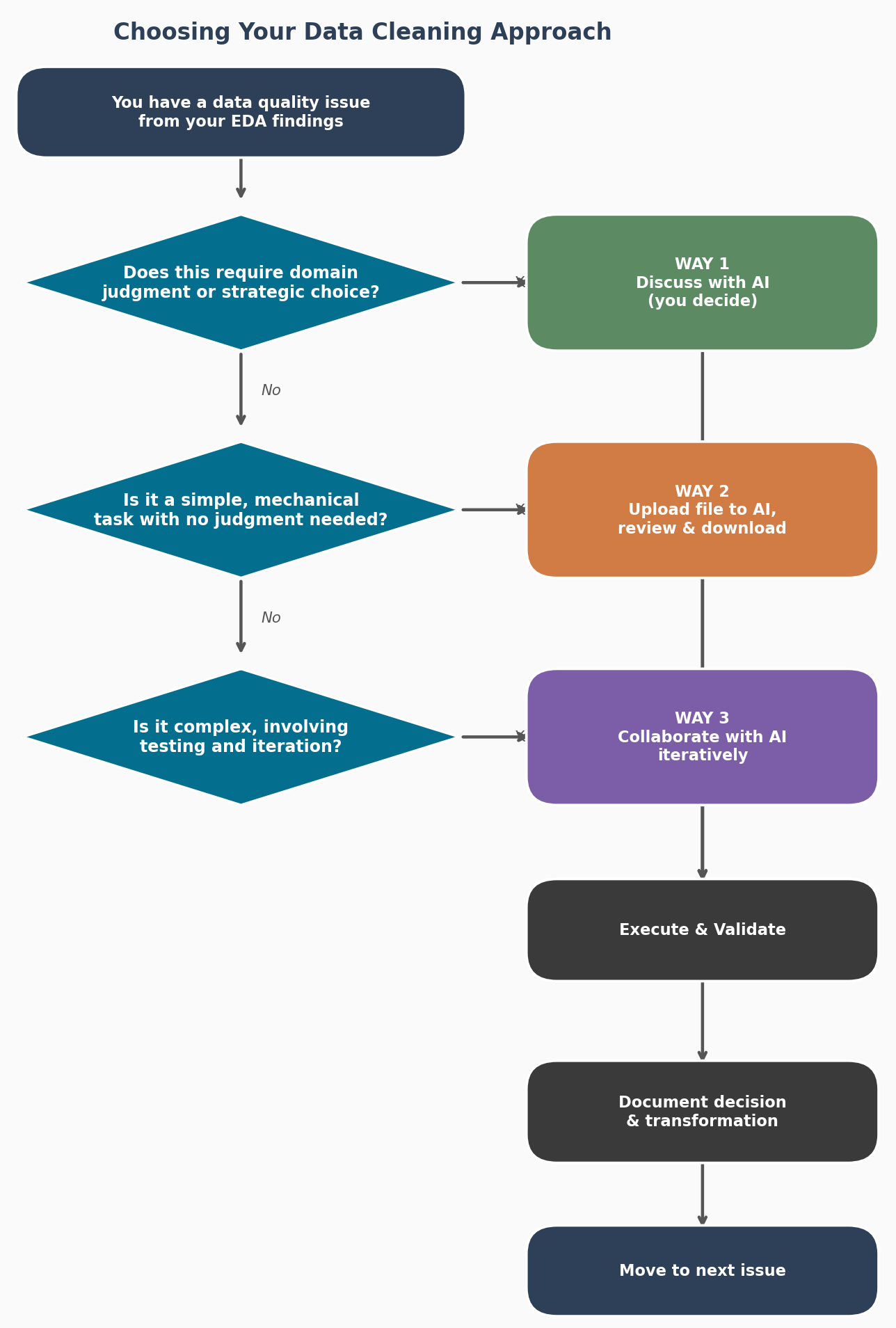
Figure 15.1 Start with each issue from your EDA findings and work through these questions to decide how to approach it. The three Ways are not rigid categories – think of them as a guide for allocating your attention.
Way 1: Discuss with AI (The Most Important)
These are decisions where the stakes are high or your domain knowledge is what matters. You are not asking AI to write code. You are asking AI to help you reason through options, because the decision itself requires you.
When to use this approach:
Deciding how to handle missing data in a key variable
Determining whether outliers are measurement errors or real phenomena
Choosing how to standardize or transform a variable
Deciding whether to merge, split, or collapse categories
What a conversation looks like:
Say you are working with a longitudinal survey of household energy consumption. About 8% of the monthly usage readings are missing, and after checking you find they cluster in summer months for a specific region. You tell AI what you found: “I have monthly energy consumption data with 8% missing values. They are concentrated in July and August for households in the Southwest. Should I delete those rows, impute from neighboring months, or create a missing indicator?”
AI walks through the options with you. What assumptions does forward-fill make? How would listwise deletion affect regional representation in your sample? What would a missing indicator let you test that imputation would not? You then make the call, based on what you know about why those readings are missing and what your research question requires.
Examples of Way 1 conversations across domains:
Economics: “I have annual firm-level revenue data. Some small firms stopped reporting after 2019, which might reflect closure or just non-reporting. How should I handle these structural gaps without introducing survivorship bias?”
Environmental science: “My air quality sensor data has gaps at night, likely from a power issue at the monitoring station. When should I interpolate versus flag and exclude?”
Social science: “My survey has a sensitive question about household income that many respondents skipped. How do I choose between imputation and adding a ‘declined to answer’ category?”
Way 2: Hand It Off to AI (Simple, Low-Risk Tasks)
These are mechanical tasks where the logic is clear, the risk is low, and your judgment is not really needed. The approach is flexible depending on how you work. If you are comfortable with code, ask AI to write a script and run it yourself. If you would rather not touch code at all, many AI interfaces – including Claude – let you upload a file directly, describe what you need done, and download the corrected version. Both paths work; use whichever fits your workflow.
When to use this approach:
Converting data types (strings to numbers, text to dates)
Standardizing date or time formats across a column
Removing exact duplicate rows
Trimming whitespace or fixing capitalization inconsistencies
Splitting or combining columns in a straightforward way
Replacing non-standard missing value labels (like “N/A”, “na”, “–”) with a consistent null marker
What this looks like (code path):
You give AI a clear instruction: “Write Python code to convert all timestamps in the ‘event_date’ column from MM/DD/YYYY format to ISO 8601 format. Flag any rows that do not match the expected pattern in a new ‘date_flag’ column.”
AI generates the code. You review it, run it on a small sample, confirm it does what you intended, and apply it to the full dataset.
What this looks like (upload path):
Alternatively, you can upload the file directly to an AI interface, type something like “Standardize all values in the ‘country’ column to ISO 3166 two-letter country codes. Flag anything you are uncertain about.” AI processes the file and returns a downloadable version with the changes applied. You open it, check a sample, and keep it if it looks right.
Either way, you are still reviewing the output. Handing it off does not mean trusting it blindly.
Examples of Way 2 tasks across domains:
Linguistics: “Convert all text in the ‘response’ column to lowercase and strip punctuation.”
Public policy: “Standardize the ‘state’ column so all values use the two-letter postal abbreviation.”
Ecology: “Extract the four-digit year from the ‘collection_date’ column and store it in a new ‘year’ column.”
Any domain: “Replace all instances of ‘N/A’, ‘na’, ‘n/a’, and ‘–’ with a standard null value.”
Way 3: Collaborate Iteratively (Complex Tasks)
These tasks require more judgment, and the right approach often only becomes clear as you test things. You and AI work back and forth: AI proposes, you inspect and raise what does not look right, AI adjusts.
When to use this approach:
Building derived variables that involve multiple columns or conditional logic
Implementing domain-specific transformations that need to be verified against known examples
Writing a validation script with many interdependent checks
Joining or merging data from multiple sources where record linkage is imperfect
Handling complex missing value patterns with multiple interacting variables
What this looks like:
Imagine you are analyzing a dataset of research grants and need to calculate a “funding intensity” measure: total dollars per year of project duration, adjusted for the number of co-investigators. You describe the goal to AI and it writes a first version. You run it and spot that projects with no end date are getting dropped rather than flagged. You tell AI, it revises the handling. You run it again, check a few rows against the raw data by hand, and find the co-investigator adjustment is off for single-PI grants. Another round of revision. Eventually the logic is right and you document it.
Examples of Way 3 tasks across domains:
Political science: “I need to merge election results data with demographic data by county FIPS code. Some counties changed boundaries between surveys. Write a script that does the merge and reports how many records could not be matched.”
Education research: “Create a script that flags impossible combinations – for example, a student with a graduation year earlier than their enrollment year, or a grade level that does not match the recorded school type.”
Climate science: “I need to aggregate daily temperature readings into monthly summaries. If more than 10% of days in a month are missing, flag that month rather than computing a potentially misleading average.”
Vibe Coding: What Researchers Need to Know
If you have spent time in developer communities lately, you have probably heard the term “vibe coding.” The idea was described by AI researcher Andrej Karpathy in early 2025: rather than carefully reading and understanding every line of code, you fully delegate the implementation to AI and stay at the level of intent []. You describe what you want, AI writes it, something does not work, you paste the error back in and keep going. You are not reading the code so much as steering it from a distance.
For some tasks, this is genuinely practical. If you need a quick script to rename files, reformat a column of dates, or standardize capitalization across a table, the logic is simple enough that you can verify the output without reading every line. That is not far from Way 2 in the framework above: the task is mechanical, the outcome is easy to spot-check, and your domain judgment is not really what is being tested.
The risk for researchers comes when vibe coding drifts into Way 1 and Way 3 territory. Say you ask AI to build a derived variable that involves conditional logic across several columns, accept the first version that runs without errors, and move directly to analysis. The code worked in the sense that it did not crash. But did it handle the edge cases your research design requires? Did it make assumptions about your data structure that you never verified? If you cannot answer those questions, you have not just delegated the coding. You have delegated a methodological decision.
This matters when it comes time to defend your work. If a reviewer or committee member asks how you handled a particular transformation, “the AI wrote it and it ran” is not a sufficient answer. Reproducibility in the fullest sense means being able to explain every step in your pipeline, not just re-run it. The three-way framework in this chapter is a guide to where your attention belongs. Vibe coding is a reasonable shortcut where that attention is optional. It becomes a problem where it is not.
A useful check: if you could not explain the logic in plain English before asking AI to code it, that is a signal to think it through first. Once you can articulate what the code should do and why, having AI write it is just a convenience. When you cannot, the code is doing your reasoning for you.
Recommended Data Prep Workflow
Step 1: Start with Your First-Pass EDA Findings
Open the list you made in Chapter 14. What issues need fixing? In roughly what order? Some fixes are prerequisites for others: you probably need to standardize date formats before you can calculate durations, for example.
Step 2: For Each Issue, Choose Your Approach
Go through your list one issue at a time. Use Figure 15.1 to decide:
Missing values in a key variable? Way 1 (discuss your strategy first).
Inconsistent capitalization in a label column? Way 2 (hand it off or ask for the code).
Derived variable with conditional logic across multiple fields? Way 3 (collaborate and test).
Step 3: Execute and Validate
For Way 1, take the time to think and decide before you touch the data. For Way 2, review the output (code or downloaded file), test on a sample, deploy to the full dataset. For Way 3, iterate with AI until you are confident, then do a final check on the full dataset.
Step 4: Document Every Decision
Before you move on, write down what you did and why. One sentence is enough: “Imputed median monthly usage for rows with missing values in summer months; gaps concentrated in Southwest region, likely sensor outage rather than systematic missingness.” This becomes part of your data documentation and is essential for reproducibility.
Validation is Non-Negotiable
Regardless of which approach you used, validation is what keeps cleaning honest.
Essential validation steps:
Compare distributions before and after. Did anything shift that should not have?
Manually inspect a sample of transformed records. Does the output match your intent?
Check for introduced bias. Did your cleaning process systematically remove certain groups or time periods?
Verify reproducibility. Can you run the same process again and get identical results?
Check for data leakage if you are preparing data for modeling (transformations based on the full dataset can leak information from test rows into training features).
Validation Checklist
Before you call your data clean:
✅ Have you reviewed the code or AI-generated output, not just accepted it?
✅ Have you tested on a sample before applying to the full dataset?
✅ Do the before-and-after distributions make sense?
✅ Have you manually spot-checked a handful of transformed records?
✅ Have you documented the reason for every transformation?
✅ Can you reproduce these transformations exactly from scratch?
Common Pitfalls
Pitfall 1: Trusting AI without understanding the logic
AI can generate code that looks right but makes wrong assumptions. Always understand what the code is doing before you run it on your full dataset. If you cannot explain it in plain language, ask AI to explain it first.
Pitfall 2: Over-cleaning
It is tempting to remove every unusual record or fill every gap. Resist this. Data is messy for reasons that sometimes matter. Clean strategically: fix what is wrong, preserve what is real, and be explicit about judgment calls.
Pitfall 3: Forgetting to document
Six months from now, you will not remember why you made a particular decision. Document decisions as you go, not at the end.
Pitfall 4: Not validating on a sample first
Always test on a small subset before running code on your full dataset. This is where you catch the case where AI got the logic slightly wrong, before it propagates.
Key Takeaways
🎯 Start with your EDA findings from Chapter 14; do not clean without a clear issue list
🎯 Use AI as a thinking partner (Way 1) when the decision itself requires domain judgment
🎯 Hand off or ask for code (Way 2) for simple mechanical tasks, and review the output either way
🎯 Collaborate iteratively (Way 3) when the logic is complex or needs testing to get right
🎯 Always validate before trusting the output
🎯 Document everything: what you did and why
Try This
For your next cleaning project:
List the data quality issues you found in first-pass EDA
For each issue, apply the three-question decision: Way 1, 2, or 3?
Execute each approach using the framework above
Validate your results before moving to the next issue
Write a one-paragraph summary of what you cleaned and why
Resources for Hands-On Learning
Kaggle Learn offers micro-courses on data cleaning with practical, worked examples. The courses include guided notebooks where you can see the three-way framework in action: thinking through a strategy, executing simple transformations, and iteratively building complex validation scripts. They are freely available at kaggle.com/learn.